In this follow up Python post I reproduce the ‘prompt sensitivity’ issue I identified last year, in an OpenAI model, in an open source model running locally. I also discover that the quantization process, which shrinks models and can make them easier to run locally, is apparently responsible for this quirky behaviour. Because the closed-source model I used in my earlier blog, text-davinci-003, is no longer available this blog opens up a path for further, reproducible, exploration of this issue.
Note: All models created for this blog, together with the imatrix.dat file discussed below, are available in a repository on my Hugging Face account here.
Introduction
‘Prompt sensitivity’ is an issue where small, and seemingly inconsequential, changes to prompts submitted to large language models (LLMs) can produce significant and unexpected changes in model outputs. It’s by no means the only concern about model prompting,1 but is an odd phenomenon because prompts which appear semantically identical to humans can elicit different responses.2 A year ago, I demonstrated this quirky behaviour in one of OpenAI’s models, text-davinci-003, while performing sentiment analysis on a well-known IMDB movie review dataset.
I’ve become slightly miffed by OpenAI’s deprecation of text-davinci-003, meaning that it’s no longer possible to reproduce these results. I therefore wanted to see if I could demonstrate prompt sensitivity in open source models, likely to be available indefinitely. I also wanted to investigate this locally on my home computer, rather than via an API, to permit more hands-on experimentation.
It turns out I didn’t need to look very far. Literally the second open source model I tried, a quantized3 (compressed) version of Mistral and NVidia’s Mistral NeMo Instruct 12 billion parameter model, displayed prompt sensitivity.4 This was also evident in the first 20 movie reviews from the IMDB dataset.
There was a twist, though. The prompt sensitivity only appeared when a specific form of quantization was used, so-called ‘importance matrix’ (imatrix) quantization. This method attempts to preserve some model weights, and by extension LLM capabilities, at the expense of others during the compression process. With default quantization, prompt sensitivity wasn’t observed (at least in the first 100 movie reviews).
I discuss this further below, but it’s worth mentioning a few caveats at this stage:
-
I’ve tested a sample of 100 out of 25,000 movie reviews in the IMDB dataset, with the first 20 documented below. More extensive testing wasn’t really feasible: one pass of all 25,000 reviews would take over 17 hours on my Mac. One solution would be to use statistical sampling techniques – potentially a topic for another blog, but for my purposes the main point is that different quantization techniques can create different models with strikingly different behaviours.
-
Sentiment analysis with IMDB reviews isn’t exactly best way to test for prompt sensitivity! Prompt sensitivity was an incidental finding from an earlier blog which piqued my curiosity, and it made sense to use that approach again here for consistency. There are more serious methods for testing for prompt sensitivity, such as PromptEval,5 which it would definitely be good to explore.
-
Thus far I’ve demonstrated this issue with one open source model. It would be interesting to check whether other open source models, like Meta’s Llama 3, can develop prompt sensitivity when quantized via specific methods. This seems like a good bet, but remains a hypothesis.
-
Finally, research is fast-moving in this area. The literature about different quantization approaches, for example, is complicated and evolving,6 as is research into how quantization can affect model performance.7 I couldn’t find any papers discussing ‘prompt sensitivity’ as a specific issue following quantization, though.
These caveats aside, I found these experiments fairly eye-opening and hope you find them interesting too.
Quantization and methodology
There are many different quantization types for LLMs, which can be confusing to the uninitiated. I won’t delve into the differences between these types here, as there are detailed guides online.8 Broadly, though, 5-bit compression offers a good balance between model accuracy, which tends to diminish as weights are stored with less precision, and resource use, which increases substantially as model weights are stored with greater precision. On my personal computer, an M2 Mac Mini with 24GB RAM, I tend to default to 5-bit models: in general, this means less worrying about things like swap memory use, which slows things down and is potentially unhealthy for SSDs.9
As noted earlier, prompt sensitivity was seen in an imatrix-quantized version of Mistral NeMo Instruct. I’d love to be able to say that my starting point was a place of deep engagement with the existing literature and a hypothesis about imatrix-quantization. But that would be to completely misrepresent my knowledge-level at that stage.
The reality was more exploratory. A short version is something like this:
- After some initial testing, with Zephir 7B Alpha which showed no prompt sensitivity in quick tests, prompt sensitivity was spotted in a Mistral NeMo Instruct 5-bit quantized model.10
- I then realised my system could cope with a less compressed model, as there was RAM to spare, and tried a corresponding 8-bit model downloaded from the same source.
- prompt sensitivity was not seen in this version, though, suggesting that the sensitivity was introduced by the quantization process itself.
- I then tried to reproduce these results by creating quantized models myself, using a script bundled with llama.cpp,11 but when I did this I didn’t see prompt sensitivity in either the 5-bit or 8-bit versions.
- It was at that point that I took a closer look, and noticed that the downloaded models had used imatrix-quantization whereas I had used a default settings in the llama.cpp script. It became clear, therefore, that I needed to reproduce imatrix-quantization specifically.
- I then set about doing this, but realised swiftly that my Mac couldn’t cope with this (it requires holding a ~25GB 16-bit model in memory, and the prospect of 3+ hours of swap on my Mac Mini didn’t seem enticing).
- So, I decided to use some GPU credits I had with an online service (LightningAI - no plug/endorsement intended, but it worked well), and used an L40S GPU which calculated the necessary imatrix
.datfile for this process in about 50 minutes:

- It was then a simple matter to create the imatrix-quantized 5-bit and 8-bit models on my Mac, using this
.datfile – and, hurrah, I reproduced what I’d seen in the downloaded models (i.e. prompt sensitivity seen in the 5-bit model, and not seen in the 8-bit model)
There is obviously more that could be said about these steps. I’d like to prevent this blog from becoming too long, though, so will move on at this point (I may add some more content on this soon).
I’ve uploaded the four models I created, with and without imatrix quantization, as well as the imatrix.dat file, to a repository on my Hugging Face account here.
Local inference (imatrix-quantized 5-bit model)
For these tests, I used the llama-cpp-python library to interact with Mistral-NeMo-Instruct-2407 models on my Mac. This library is a Python wrapper for the excellent llama.cpp, an Apple Silicon-friendly C++ library for LLM inference.12
As this is a continuation of my earlier blogs, I used the code for these as a starting point. Just a couple of edits were needed to my original code for this part of the experiment, primarily to replace the use of the OpenAI API with code for local inference with llama-cpp-python:
# import llama-cpp-python package
from llama_cpp import Llama
# specify path (replace $MODEL_DIR with the path on your system)
llm_path = "$MODEL_DIR/Mistral-Nemo-Instruct-2407-Q5_K_M.gguf"
# initialise the model
llm = Llama(model_path=llm_path,
n_gpu_layers=-1, # offloads model layers to GPU
temperature = 0, # minimise model 'creativity'
n_ctx=1024) # ensure large enough context window for reviews
In addition to importing llama-cpp-python,13 and offloading all model layers to GPU,14 this also sets the model temperature to 0. This temperature setting is important because we’re looking for reproducible results rather than any model ‘creativity’.
As regards the context window size (n_ctx), I used the helpful gpt3_tokenizer library to calculate the maximum token count of the reviews:
import gpt3_tokenizer
# fetch the imdb dataset from Hugging Face
from datasets import load_dataset
imdb = load_dataset("scikit-learn/imdb")
# calculate tokens (using a list comprehension to loop through the reviews and store in a list)
tokens = [gpt3_tokenizer.count_tokens(imdb['train']['review'][n]) for n in range(20)]
# print number of tokens of the largest review
print(max(tokens))
## 523
A 1K context window, therefore, was more than enough.
The function to classify the reviews was essentially identical to the one used earlier.15 The only change here was the “Get completion from the model” element, where the openai.ChatCompletion element was replaced with the relevant llama-cpp-python code:16
def classify_sentiment(prompt, slice_size=20):
# Initialise list to store predicted sentiments
predicted_sentiments = []
# Extract reviews based on the slice_size
reviews = imdb['train']['review'][:slice_size]
# Iterate over the sliced items
for review in reviews:
# Construct the full prompt
full_prompt = f"{prompt}: {review}\nSentiment:"
# Get completion from the model
response = llm(full_prompt, max_tokens=1, temperature=0)
# Extract the sentiment label from the output
predicted_sentiment = response['choices'][0]['text'].strip().lower()
# Add the predicted sentiment to the list
predicted_sentiments.append(predicted_sentiment)
# Create a DataFrame from the reviews and predicted sentiment labels
df = pd.DataFrame({
'Review': reviews,
'Sentiment': predicted_sentiments
})
return df
With that done, it was then possible to run the tests.
Sentiment classification (imatrix-quantized 5-bit model)
I kept things simple here, and did the same comparison as before i.e.:
prompt1 = "Classify the sentiment of this movie review as positive or negative"
prompt2 = "Classify the sentiment of this movie review as either positive or negative"
After running inference…
results1 = classify_sentiment(prompt1, slice_size=20)
results2 = classify_sentiment(prompt2, slice_size=20)
…the significant results can be seen here:
results1.tail()
## Sentiment
## Review
## Kind of drawn in by the erotic scenes, only to ... negative
## Some films just simply should not be remade. Th... negative
## This movie made it into one of my top 10 most a... negative
## I remember this film,it was the first film i ha... positive
## An awful film! It must have been up against som... negative
results2.tail()
## Sentiment
## Review
## Kind of drawn in by the erotic scenes, only to ... negative
## Some films just simply should not be remade. Th... negative
## This movie made it into one of my top 10 most a... negative
## I remember this film,it was the first film i ha... negative
## An awful film! It must have been up against som... negative
As can be seen, there was a difference with the penultimate classification from first batch of 20 reviews. The other 19 classifications were identical.
Visualising prompt sensitivity
Let’s now look at the results, using the compare_labels function from earlier:17
compare_labels(results1, results2,
labels=["without 'either'", "with 'either'"],
title="Mistral NeMo Instruct 12B, Q5_K_M")
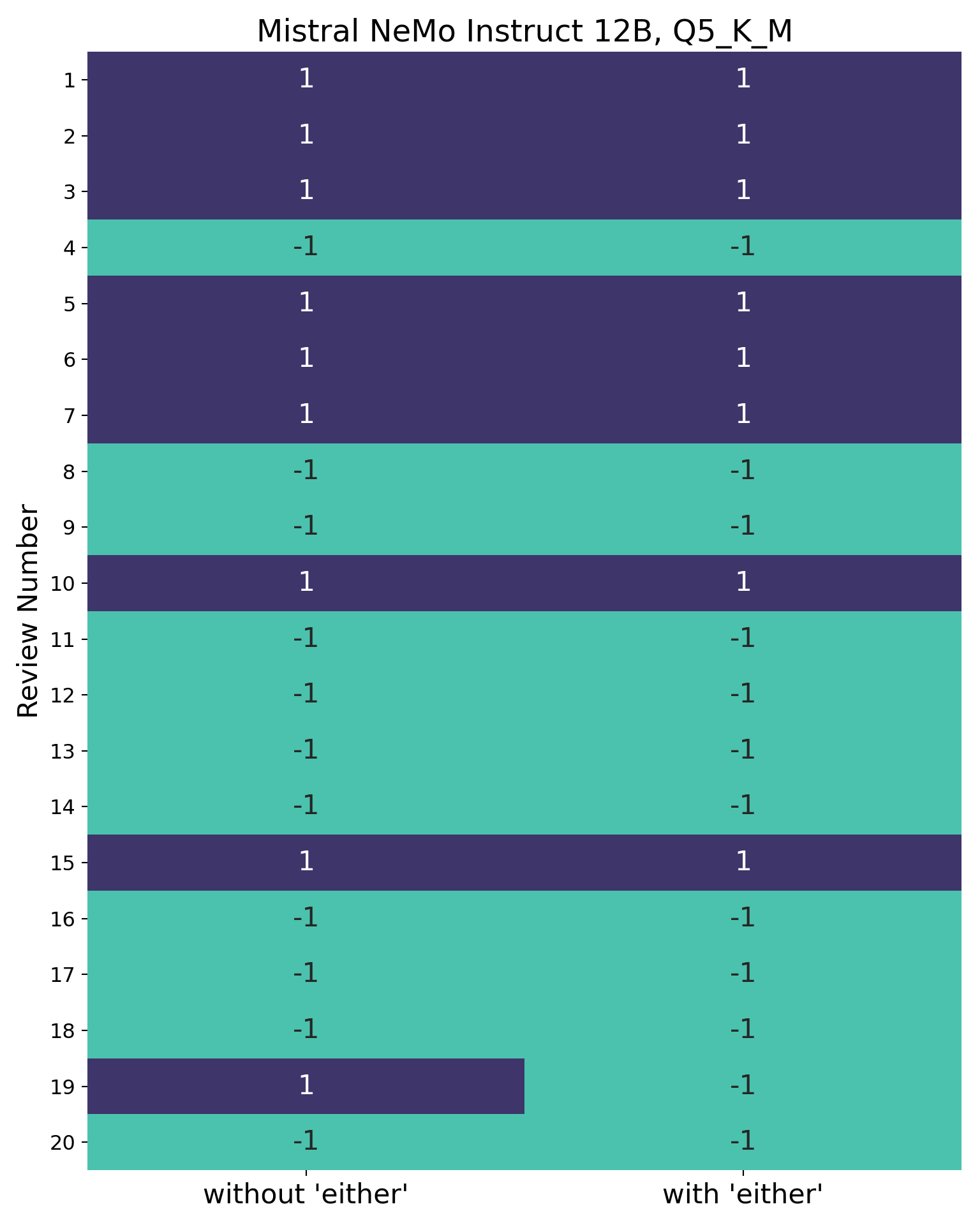
The problematic review from the first 20 reviews, it turns out, was this one:
“I remember this film,it was the first film i had watched at the cinema the picture was dark in places i was very nervous it was back in 74/75 my Dad took me my brother & sister to Newbury cinema in Newbury Berkshire England. I recall the tigers and the lots of snow in the film also the appearance of Grizzly Adams actor Dan Haggery i think one of the tigers gets shot and dies. If anyone knows where to find this on DVD etc please let me know.The cinema now has been turned in a fitness club which is a very big shame as the nearest cinema now is 20 miles away, would love to hear from others who have seen this film or any other like it.”
It’s a pretty strange review, to be honest, and like the problematic review from my earlier blog (Review 1) this could quite easily be viewed as equivocal / borderline. It’s still weird, though, that including the word “either” in the prompt changes the model output at all.
Comparing results with the 8-bit version (imatrix-quantized)
Now, finally, the outputs from the 8-bit version for comparison. I won’t go through all the code again – the only difference was to set llm_path to "$MODEL_DIR/Mistral-Nemo-Instruct-2407-Q8_0.gguf".
Creating the visualisation:
compare_labels(results3, results4,
labels=["without 'either'", "with 'either'"],
title="Mistral NeMo Instruct 12B, Q8_0")
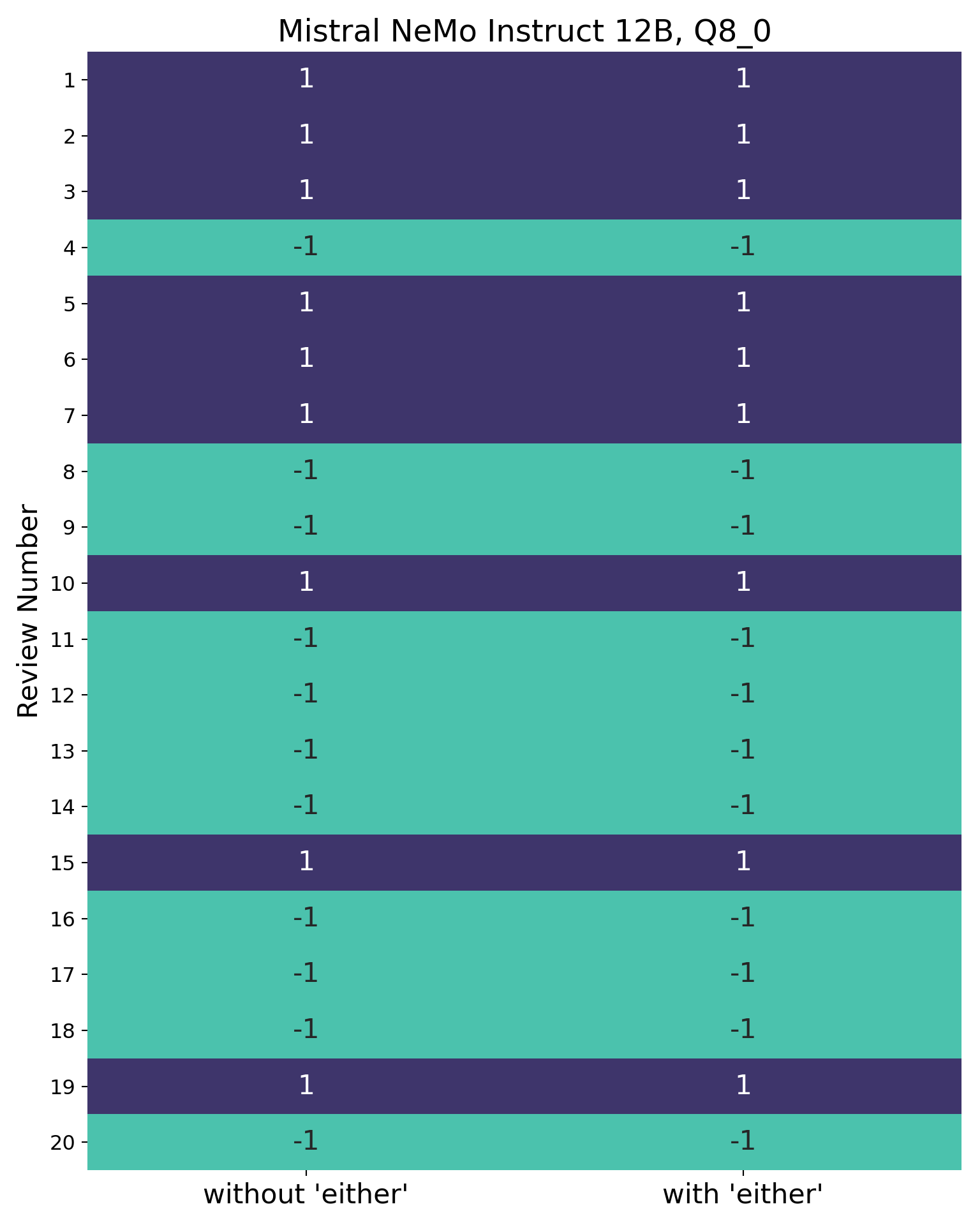
As can be seen, both versions of the prompt are processed identically.
Conclusion and future directions
Prompt sensitivity is clearly an ongoing issue for Large Language Models, and can apparently be introduced when models are quantized, but what does this mean?
There’s evidently room for a much larger discussion, and more systematic investigation, of prompt sensitivity to build on this blog – I’ll bring things to a close now, though, as I think this blog is already quite long. At least, though, some interesting questions have arisen, and should be easier to explore with open source models (access to Mistral NeMo Instruct, for example, isn’t in any danger of disappearing).
In terms of further work, there are a few threads I could follow up in future blogs:
- Statistical analysis of prompt sensitivity (using current sentiment analysis-based approach): as noted earlier, rather than testing an arbitrary block of 20 or 100 IMDB reviews it would be better to test random samples of reviews e.g. to more properly test the claim that the default llama.cpp quantization didn’t show prompt sensitivity.
- Exploring PromptEval and similar frameworks: of greater priority than this would be to explore the use of existing/in development frameworks for systematically testing the responses of LLMs to prompts. This could be combined with testing a greater number of LLMs.
- It would be good to investigate different quantization approaches more systematically, including understanding in more detail how imatrix quantization works and its benefits/risks - I’ve only just scratched the surface of this topic here.
- Implications of prompt sensitivity, and mitigations: I’ve not considered the implications here, but there is clearly a larger discussion to be had about what this phenomenon means in practice, and how to mitigate these issues.
-
e.g. https://shelf.io/blog/understanding-the-influence-of-llm-inputs-on-outputs/. ↩︎
-
See, for example: Sclar et al 2023, “Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting” https://arxiv.org/abs/2310.11324v2 ; Federico et al. 2024, “What Did I Do Wrong? Quantifying LLMs’ Sensitivity and Consistency to Prompt Engineering.” https://arxiv.org/abs/2406.12334 ↩︎
-
I’ve decided to use the US spelling of ‘quantized’, rather than the UK spelling ‘quantised’, due its widespread use in the technical literature in this area. ↩︎
-
For further information on this model, see e.g.: https://mistral.ai/news/mistral-nemo/; https://unfoldai.com/mistral-nemo-12b-review/; https://www.hyperstack.cloud/blog/thought-leadership/all-you-need-to-know-about-mistral-nemo. ↩︎
-
See Maia Polo et al. 2024, “Efficient multi-prompt evaluation of LLMs” https://arxiv.org/abs/2405.17202v2, and https://github.com/felipemaiapolo/prompteval. ↩︎
-
The complexity is lamented here: https://github.com/ggerganov/llama.cpp/discussions/5063. For further discussion of quantization, including importance matrices and underlying theory, see: https://symbl.ai/developers/blog/a-guide-to-quantization-in-llms/, this blog by Maarten Grootendorst https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization; and Benedek et al. (2024), “PRILoRA: Pruned and Rank-Increasing Low-Rank Adaptation” https://arxiv.org/abs/2401.11316. ↩︎
-
For example, quantization can disproportionately impact some capabilities of LLMs more than others: Marchisiol et al. 2024 “How Does Quantization Affect Multilingual LLMs?” https://arxiv.org/abs/2407.03211v1. ↩︎
-
See e.g. https://www.tensorops.ai/post/what-are-quantized-llms and https://symbl.ai/developers/blog/a-guide-to-quantization-in-llms/. ↩︎
-
Quantized by Bartowski, and available here: https://huggingface.co/bartowski/Mistral-Nemo-Instruct-2407-GGUF. I opted for the
Q5_K_Mquantization type. ↩︎ -
For further details, see https://github.com/ggerganov/llama.cpp/blob/master/examples/quantize/README.md, and for a helpful blog on this process see https://medium.com/@ingridwickstevens/quantization-of-llms-with-llama-cpp-9bbf59deda35. ↩︎
-
For a helpful overview of the benefits and drawbacks of running LLMs locally versus on the cloud, see e.g. https://www.datacamp.com/blog/the-pros-and-cons-of-using-llm-in-the-cloud-versus-running-llm-locally. ↩︎
-
For installation, see https://pypi.org/project/llama-cpp-python/. ↩︎
-
See https://llama-cpp-python.readthedocs.io/en/latest/api-reference/. ↩︎
-
See the Appendix of Sentiment analysis with the OpenAI API - Part 1. ↩︎
-
For further discussion, see e.g. https://pypi.org/project/llama-cpp-python/, and https://www.datacamp.com/tutorial/llama-cpp-tutorial. ↩︎
-
See the Appendix of Sentiment analysis with the OpenAI API - Part 1. Here I’ve added a count of y-axis labels to make interpretation easier. ↩︎